大数据理论篇 | 分布式SQL引擎Inceptor
一、 Inceptor简介
1)什么是Inceptor
- 概念
- 用于数据仓库和交互式分析的大数据平台软件
- 基于Hadoop的数据仓库产品
- 分布式通用SQL引擎
- 基于Hive和Spark技术打造
- 特点
- Hadoop领域对SQL支持最完善
- 支持SQL 2003语法与存储过程
- 业内唯一支持Oracle方言
- 业内唯一支持DB2方言
- 业内唯一支持Teradata方言
- 帮助用户低成本迁移传统应用
- 支持完整分布式事务处理
- 保证分布式事务处理的ACID特性
- 支持批量增删改查的分布式事务处理
- 使用MVCC(Multi-Version Concurrency Control)算法自动提供并发控制
- 优异的大数据处理和分析性能
- 基于内存/SSD的列式存储支持对数十亿条记录的秒级交互式分析
- 与Apache Hive相比,数据分析处理速度有显著提升
- 对于大规模数据集,数据分析处理速度比MPP有显著提升
- 提供便捷的SQL、PL/SQL开发调试辅助工具Waterdrop
- Hadoop领域对SQL支持最完善
2)Inceptor适用场景
- 离线分析
- 批处理
- 交互式分析
- 图计算、图检索
3)项目应用
- BI报表工具(JDBC/ODBC)
- SQL IDE开发工具(Waterdrop)
- Web应用系统(JDBC / ODBC)
- 数据加工工具(SQL / PLSQL)
二、 Inceptor原理
1)系统架构
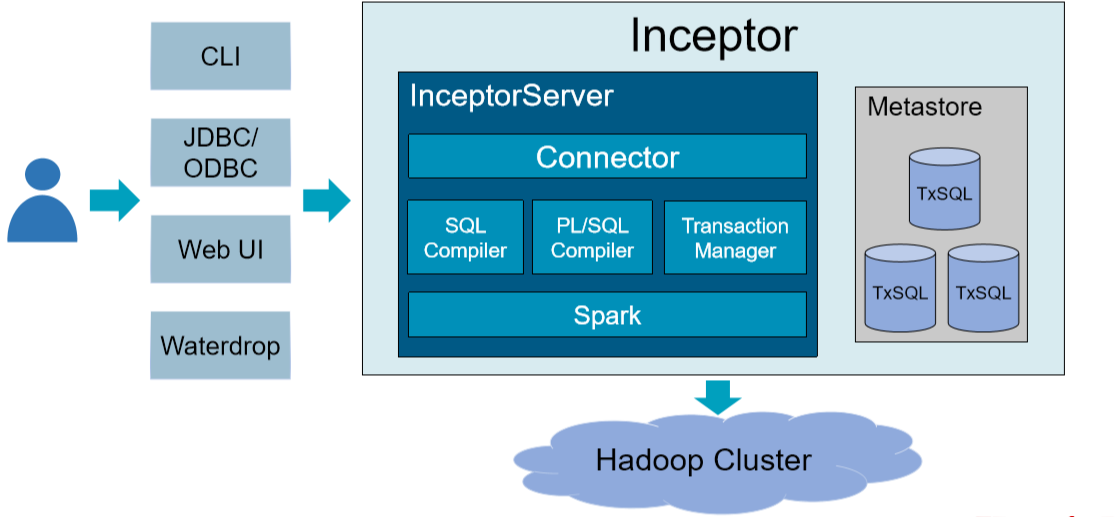
InceptorServer计算引擎
- Connector:为BI、ETL工具提供标准JDBC、ODBC接口
- SQL Compiler
- SQL Parser:SQL语法解析器
- Rule-based & Cost-based Optimizer:规则和代价优化器
- Code Generator:代码生成器
- PL/SQL Compiler
- Procedure Parser:存储过程解析器
- CFG Optimizer:控制流优化器
- Parallel Optimizer:并行优化器
- Transaction Manager
- Distributed CRUD:分布式增删改
- Concurrency Controller:事务并发控制器
- Spark
- 官方认证Transwarp发行版
- 大数据量下的高稳定性、计算效率更高、功能扩展
- 计算资源
- Executor是资源调度的基本单元
- Web可视化配置
- Metastore
- 存储Inceptor元数据
- 元数据主要包括:数据库、表、分区、分桶等信息
- 元数据存储在TxSQL(MySQL集群)
- Client
- CLI:Beeline
- JDBC/ODBC
- Web UI
- HUE:开源的Apache Hadoop UI系统
- Polit:星环打造的轻量级自助式BI分析工具
- Waterdrop
- 高效的Inceptor SQL IDE工具
- 支持主流的关系数据库和数据仓库,如:Oracle、DB2、MySQL、Hive、Teradata、SAP等
2)数据模型
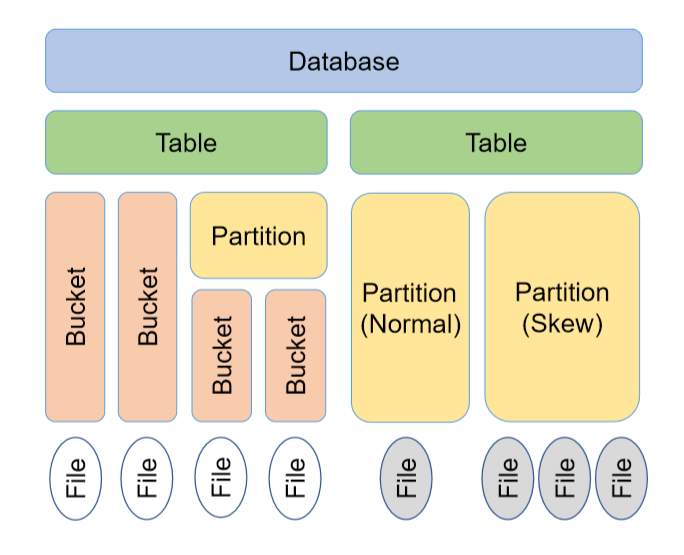
2.1 数据库(Database)
- 数据库是一个包含若干表的命名空间和磁盘目录,类似于RDBMS(关系数据库管理系统)中的数据库
- 系统会为每个数据库创建一个目录,目录名=数据库名.db
- 通常无法删除包含表的数据库,应该先删除表,再删除数据库
2.2 表(Table)
- 表是数据管理和存储的基本对象,包含若干字段,类似于RDBMS中的表
- 表的元数据存储在Metastore中,表的实际数据存储在HDFS、Holodesk、Hyperbase和Search中
表(Table)的分类:
1)按所有权分类
- 托管表(Managed Table,又称内部表、内表)
- 系统具有内表的完全控制权,负责管理它的生命周期
- 元数据存储在Metastore中,表数据通常存储在所属数据库目录下的对应子目录中,目录名=表名
- 删除内表时,会同时删除表数据,以及Metastore中的元数据
- 外部表(External Table,又称外表)
- 系统不具有外表的完全控制权
- 元数据存储在Metastore中,表数据通常存储在指定的外部存储目录中
- 删除外表时,不会删除表数据,但会删除Metastore中的元数据
2)按存储格式分类
- Text表
- 系统默认的表类型,无压缩,行存储,仅支持批量Insert
- 分析查询的性能较低,主要用于导入原始文本数据时建立过渡表
- ORC表
- 优化的列式存储,轻量级索引,压缩比高,仅支持批量Insert
- Inceptor计算的主要表类型,适用于数据仓库的离线分析,通常由Text表生成
- ORC事务表
- 由ORC表衍生而来,继承了ORC表的所有特性,支持完整CURD(单条和批量Insert、Update、 Delete),以及分布式事务处理
- 多版本文件存储,定期做压缩,10~20%的性能损失
- Holodesk表
- 基于内存/SSD的列式存储,内置索引和Cube,速度快,压缩率比ORC表略低,仅支持批量Insert
- 适用于海量数据的大批量、复杂、高性能查询,如:交互式分析和报表可视化展现
- Hyperbase表
- 数据存储在Hyperbase上,支持多种索引,以及Insert、Update、Delete
- 适用于高并发的历史数据查询,支持半结构化、非结构化数据存储
- ES表
- 原始数据和索引数据都存储在ElasticSearch中,支持模糊查询和全文检索,适用于综合搜索
2.3 分区(Partition)
- 目的:减少不必要的全表扫描,提升查询效率
- 含义:将表按照某个或某几个字段(分区键)划分为更小的数据集
- 分区数据存储于表目录下的子目录中,一个分区对应一个子目录,目录名为“分区键=value”
- 如何选择分区键
- 分区键通常高频出现在Select … Where条件查询中
- 为了避免产生过多的子目录和小文件,只对离散字段进行分区,如日期、地域、民族等
- 由于HDFS不支持大量的子目录,有必要对分区数量进行预估
- 预估分区的数据量,避免数据倾斜
2.4 分桶(Bucket)
- 含义:通过分桶键哈希取模(key hashcode % N)的方式,将表或分区中的数据随机、均匀地分发到N个桶中,桶数N一般为质数,桶编号为0, 1, …, N-1
- 作用
- 数据划分:随机均匀
- 数据聚合:Key相同的数据在同一个桶中
- 存储
- 在表或分区目录下,每个桶存储为一个文件
- 桶文件的大小应控制在100~200MB之间(ORC表压缩后)
- 如果桶文件小于HDFS Block,那么一个桶对应一个Block,否则会存储在多个Block中
- 作用
- 提高Join查询效率:如果两个表的Join列都做了分桶,且分桶数相同或成倍数,那么相同列值的数据会分到编号相同或有对应关系的桶中,这样就不用全表遍历,对对应的桶做Join就可以了
- 提高取样效率:从桶中直接抽取数据
- 用法
- 通常先分区后分桶
- 分桶键和分桶数在建表时确定,不允许更改
2.5 读时模式
- 含义:数据写入数据库时,不检查数据的规范性,而是在查询时再验证
- 特点:
- 数据写入速度快,适合处理大规模数据
- 查询时处理尺度很宽松,尽可能恢复各种错误
三、 Inceptor SQL
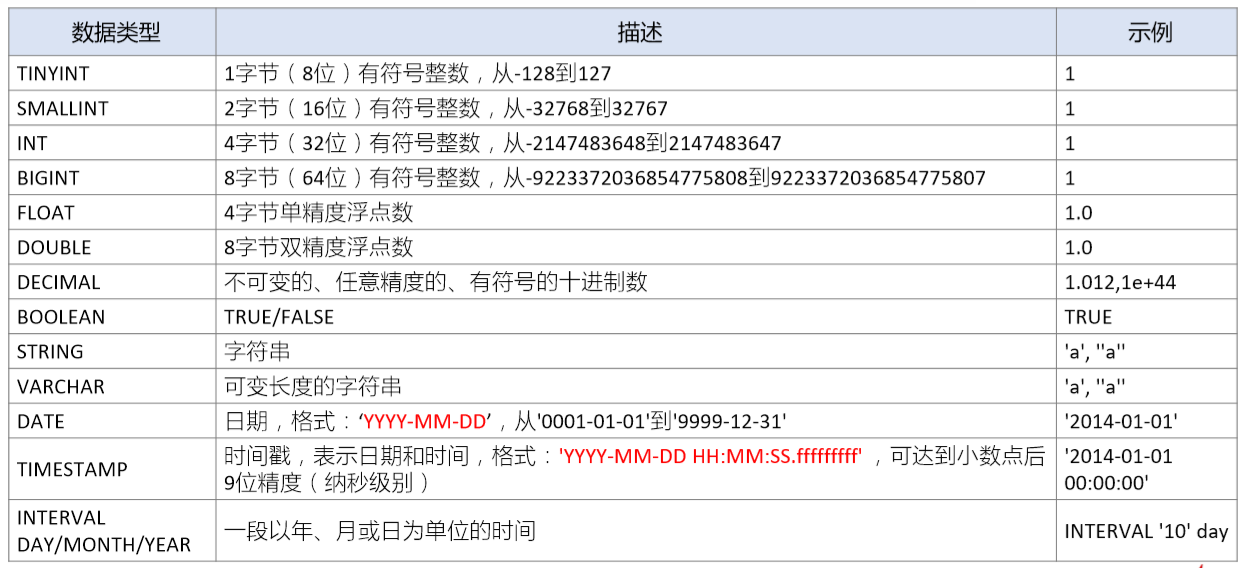
1)SQL数据类型
基本数据类型
复杂数据类型

2)SQL DDL
表的高级操作:
- 分区
- 分区表将数据按分区键的键值存储在表目录的子目录中,目录名为“分区键=键值”
- Inceptor只支持TEXT表、ORC表、CSV表和Holodesk表的分区操作
- 单值分区:一个分区对应分区键的一个值
- 范围分区:一个分区对应分区键的一个范围(区间)
1.1 单值分区
- 创建单值分区时,分区键不能和表结构中的列重复,因为分区键已存储在分区目录名中,分
区数据中不包含分区键,否则会造成数据冗余 - 单值分区可以分成两类
- 单值静态分区:导入数据时,必须手动指定目标分区
- 单值动态分区:导入数据时,系统可以动态判断目标分区
1.2 范围分区
- 每个分区对应分区键的一个区间,凡是落在指定区间内的记录都被存储在对应的分区下
- 各范围分区按顺序排列,前一个分区的最大值即为后一个分区的最小值
- 分桶
- 含义:按分桶键哈希取模的方式,将表中数据随机、均匀地分发到若干桶文件中
- 目的:通过改变数据的存储分布,提升取样、Join等特定任务的执行效率
- 与分区键不同,分桶键必须是表结构中的列
- 分桶表在创建的时候只定义Schema,且数据写入时系统不会自动分桶,所以需要先人工分桶再写入
- 写入分桶表只能通过Insert,而不能通过Load,因为Load只导入文件,并不分桶
- 如果分桶表创建时定义了排序键,那么数据不仅要分桶,还要排序
- 如果分桶键和排序键不同,且按降序排列,使用Distribute by … Sort by分桶排序
- 如果分桶键和排序键相同,且按升序排列(默认),使用Cluster by分桶排序
- 分桶键和分桶数在建表时确定,不允许更改
- ORC事务表必须分桶
- 通常先分区后分桶
- 函数操作
3)SQL DML
- 数据导入
- Load导入
- Insert导入
- 数据导出:Insert导出
- 查询:Select…From
注意:
- 常见的DML只能用于ORC事务表、Hyperbase表。例如:单行数据的增删改操作,Insert values Into、Delete、Update
- 如果写入普通表,则将指定的文件或查询结果放入表对应的目录中,该目录不能有子目录
- 如果写入分区表,则必须将文件放入对应的分区目录中
数据导入
- 数据预处理:将文件编码转换为UTF-8,将换行符统一为Unix下的换行符\n
- 将文件导入表或分区
- 这里有Load导入和Insert导入两种方式
- Load导入不支持动态分区导入,不推荐使用Load导入数据,因为在安全模式下的权限设置步骤较多。推荐的数据导入方法是:创建外表,并将外表Location设置为数据文件所在目录
- Insert导入又有单值静态分区导入、单值动态分区导入之分,静态分区存在的问题是需要手工输入大量的Insert语句,动态分区写入无需手工指定分区,而是让系统根据查询结果自动推断出分区。
数据导出
将数据导出到本地或HDFS(Insert导出)
- 将查询结果导出到本地目录,可能生成多个文件
- 与导入数据不一样,不能用Insert Into导出数据,只能用Insert Overwrite
Select查询
- 过滤:Where、Having
- 排序:Order By、Sort By
- 分桶与聚合:Distribute By、Cluster By、Group By
- 连接:Join
Distribute By
- 通过哈希取模的方式,实现数据按Distribute By列值分桶
- 将Distribute By列值相同的数据发送给同一个Reduce任务,实现数据按指定列聚合
- 通常与Sort By合并使用,实现先聚合后排序,且Distribute By必须在Sort By之前
Cluster By
- 如果Distribute By列和Sort By列完全相同,且按升序排列,那么Cluster By = Distribute By … Sort By