大数据理论篇 | 分布式ETL工具Sqoop
分布式ETL工具Sqoop
零、 写在前面
- ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
- ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
- ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
- ETL是BI(商业智能)项目重要的一个环节。
- Sqoop最早期是Hadoop的模块,所以Sqoop底层做的是MapReduce任务,通过将我们的导入导出命令翻译成MapReduce程序来完成作业,通过MapReduce将数据从数据库导到HDFS,或是从HDFS导入数据库。这一点和我们的Hive类似。
一、 Sqoop简介
1)什么是Sqoop
- Sqoop项目始于2009年,早期为Hadoop的第三方模块,后来成为Apache的独立项目
- Sqoop是一个主要在Hadoop和关系数据库之间进行批量数据迁移的工具
- Hadoop:HDFS、Hive、HBase、Inceptor、Hyperbase
- 面向大数据集的批量导入导出
- 将输入数据集分为N个切片,然后启动N个Map任务并行传输
- 支持全量、增量两种传输方式
- 提供多种Sqoop连接器
- 内置连接器
- 经过优化的专用RDBMS(关系数据库管理系统)连接器:MySQL、PostgreSQL、Oracle、DB2、SQL Server、Netzza等
- 通用的JDBC连接器:支持JDBC协议的数据库
- 第三方连接器:
- 数据仓库:Teradata
- NoSQL数据库:Couchbase
- 内置连接器
2)Sqoop版本
- Sqoop1 与Sqoop2 的区别
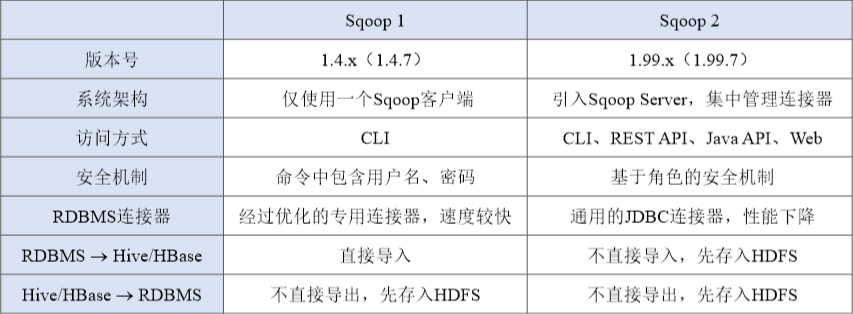
- 二者完全不兼容,无法平滑升级
- Sqoop1优缺点
- 优点:
- 架构简单
- 部署简单
- 功能全面
- 稳定性较高
- 速度较快
- 缺点
- 访问方式单一
- 命令行方式容易出错,格式紧耦合
- 安全机制不够完善,存在密码泄露风险
- 优点:
- Sqoop2优缺点
- 优点:
- 访问方式多样
- 集中管理连接器
- 安全机制较完善
- 支持多用户
- 缺点:
- 架构较复杂
- 部署较繁琐
- 稳定性一般
- 速度一般
- 优点:
- 实际工作中推荐使用Sqoop1,至于角色多用户的问题,在实际中数据采集操作基本上是一个人完成的
二、 Sqoop原理
- Sqoop主要是负责Hadoop与RDBMS之间的数据迁移,即从Hadoop文件系统 导出数据到RDBMS,从RDBMS导入数据到Hadoop hdfs,hive,hbase等数据存储系统。
- 其实就是将 sqoop命令转换成MR程序来完成数据的迁移。
- 本质就是执行和计算,依赖于hdfs存储数据,把sql转换成程序
1)数据导入
- 数据导入是指从RDBMS(关系数据库管理系统)将数据导入到Hadoop File System中
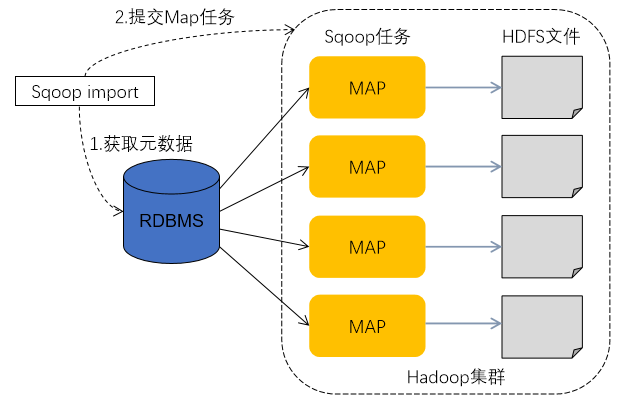

- 数据导入过程:
- Sqoop通过JDBC从数据库获取需要的元数据,如表的列名、数据类型等。这里假设导入的表名为Person表
- Sqoop将获取到的数据库数据类型(varchar、number等)映射成Java数据类型(String、int等),并生成一个与表名相同的类,如Person.java源文件,该文件实现了Writable接口,该文件生成在Sqoop执行的目录下,这个类的作用是完成序列化/反序列化工作,并且保存数据库表中的每一行记录。
- Sqoop启动MapReduce作业
- Map作业阶段读取数据库输入的过程中,是通过JDBC读取数据库表中的数据记录,此时会用Sqoop生成的Person.java类进行反序列化
- Map作业阶段输出数据写入HDFS,此时也是用Sqoop生成的Person.java类进行序列化,Sqoop默认导出格式为CSV
- 说明:
- Map多任务导入时,会对表的数据进行水平切分(默认按主键列),切分数(即Map任务数)由命令’-m’确定,如: -m 1 为单行,只有一个SQL
- 每个任务执行的SQL:如
- SELECT column1, column2, column3 FROM TABLE WHERE id >= 0 AND id < 50000;
- SELECT column1, column2, column3 FROM TABLE WHERE id >= 50000 AND id < 100000;
- ……
- 如果数据id分布不均匀,水平切分会出现数据倾斜
- 使用Sqoop进行并行导入的话,切分列的数据会很大程度地影响性能,如果在均匀分布的情况下,性能最好。在最坏的情况下,数据严重倾斜,所有数据都集中在某一个切分区中,那么此时的性能与串行导入没有差别,所以,在导入之前,有必要对切分列的数据进行抽样检测,了解数据的分布。
2)数据导出
- 数据导出是指从Hadoop文件系统中将数据导出到RDBMS中
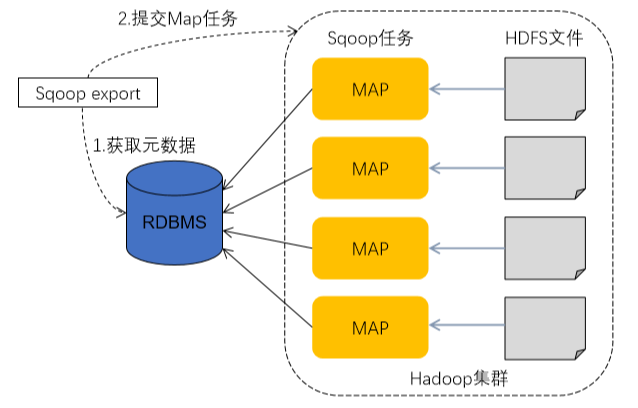

- 数据导出过程:
- Sqoop通过JDBC从数据库获取目标表结构,如表的列名、数据类型等,这里依然以Person表为例进行说明
- Sqoop将获取到的数据库数据类型(varchar、number等)映射成Java数据类型(String、int等),并生成一个与表名相同的类,如Person.java源文件,该文件实现Writable接口,生成在Sqoop执行的目录下。
- Sqoop启动MapReduce作业
- Map阶段从HDFS读取数据输入,在此过程中,是通过JDBC读取表数据文件,用Sqoop生成的Person.java类进行反序列化
- Map阶段色输出数据,写入数据库时,生成一批Insert语句,每条语句都会向数据库中插入多条数据记录
参考资料:
[1]Sqoop导入导出过程笔记
[2]Sqoop导入导出过程原理
三、 Sqoop使用
1)基本用法
- 全量数据导入
- 基于递增列的增量数据导入(Append方式)
- 基于时间列的增量数据导入(LastModified方式
- 对比Append方式,LastModified方式可导入更新数据
2)进阶用法
- 从Oracle分区表中导入数据
- 并发导入
- 通过-m参数,设置多个Map任务,实现数据并发导入
- -m大于1时,必须设置–split-by,并利用哈希取模实现数据均匀切片,避免数据倾斜
- 并发度控制