大数据理论篇 | 分布式资源管理框架YARN
一、 产生背景
Hadoop 1.X时期,MapReduce采用的也是主从架构:即master-slaves架构,一个JobTracker带多个TaskTracker。JobTracker:负责资源管理和作业调度;Tasktracker 向jobtracker定期汇报本节点的健康状况、资源使用情况、作业执行情况;同时也接收来自JobTracker的命令,负责启动和杀死任务的具体执行。MapReduce作业拆分成Map任务和Task任务,由TaskTracker负责执行和汇报。
这样的架构存在天生的缺陷:
- MapReduce同时身兼两职:既是计算框架,同时又是资源管理系统。
- 其主要角色JobTracker既做资源管理,又做任务调度,任务太重,开销过大,同时存在单点故障。
- JobTracker既要维护job的状态又要维护job的task的状态,造成资源消耗过多
- 不仅如此,早期的MR的资源描述模型过于简单,导致资源利用率较低
- 它仅把Task数量看作资源,没有考虑CPU和内存
- 强制把资源分成Map Task Slot和Reduce Task Slot,仅仅只能支持MR作业,不能支持其他计算框架(如Spark、Storm等)
- MR还存在扩展性较差(集群规模上限4K)
- 源码难以理解,升级维护困难
- 难以统一管理多个集群(如Spark集群,hadoop集群同时存在),资源利用率较低,彼此之间没有办法共享资源,运维成本高。
于是Hadoop在1.0升级到2.0的过程中,便将JobTracker的资源调度工作独立了出来,这个独立出来的资源管理框架,就是Yarn。
二、 YARN设计目标
- YARN,Yet Another Resource Negotiator,另一种资源管理器
- 定位是 分布式通用资源管理系统
- 设计目标:聚焦资源管理、通用(适用各种计算框架)、高可用、高扩展
- YARN在大数据生态中的位置,位于HDFS之上,多种计算框架、数据分析框架等应用程序之下,这样多种不同类型的计算框架都可以运行在同一个集群里面,共享同一个HDFS集群上的数据,享受整体的资源调度。也就是 XXX on YARN,例如Spark on YARN,Spark on YARN,MapReduce on Yarn,Storm on YARN,Flink on YARN。好处是与其他计算框架共享集群资源,按自愿需要分配,进而提高集群资源的利用率。
三、 YARN架构
3.1 系统架构
3.1.1 基本思想
- Master/Slave架构
- 将JobTracker的资源管理、任务调度功能分离
- 三种角色:ResourceManager(Master)、NodeManager(Slave)、ApplicationMaster (新角色)
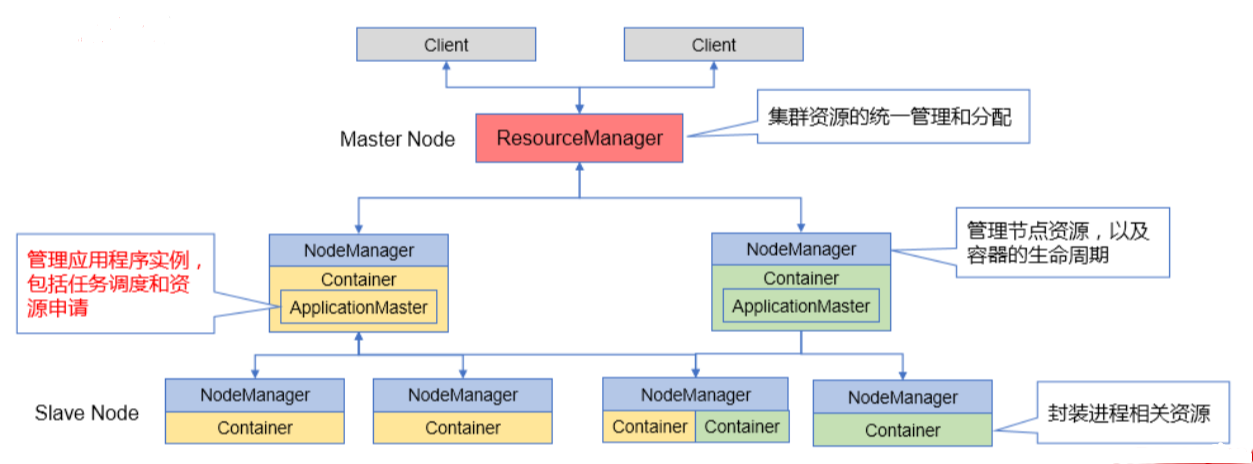
3.1.2 核心概念
1)ResourceManager(RM)
- 主要功能:
- 统一管理集群的所有资源
- 将资源按照一定策略分配给各个应用(ApplicationMaster)
- 接收NodeManager的资源上报信息
- 核心组件
- 用户交互服务(User Service)
- NodeManager管理
- ApplicationMaster管理
- Application管理
- 定时调用器(Scheduler)
- 安全管理
- 资源管理
2)NodeManager(NM)
- 主要功能
- 管理单个节点的资源
- 向ResourceManager汇报节点资源使用情况
- 管理Container的生命周期
- 核心组件
- NodeStatusUpdater
- ContainerManager
- ContainerExecutor
- NodeHealthCheckerService
- Security
- WebServer
3)ApplicationMaster(AM)
- 主要功能
- 管理应用程序实例
- 向ResourceManager申请任务执行所需的资源
- 任务调度和监管
- 实现方式
- 需要为每个应用开发一个AM组件
- YARN提供MapReduce的ApplicationMaster实现
- 采用基于事件驱动的异步编程模型,由中央事件调度器统一管理所有事件
- 每种组件都是一种事件处理器,在中央事件调度器中注册
4)Container
- 概念:Container封装了节点上进程的相关资源,是YARN中资源的抽象
- 分类:运行ApplicationMaster的Container、运行应用任务的Container
- Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器Container由 NodeManager 启动和管理,并被它所监控。
- 容器Container被 ResourceManager 进行调度
3.1.3 工作机制
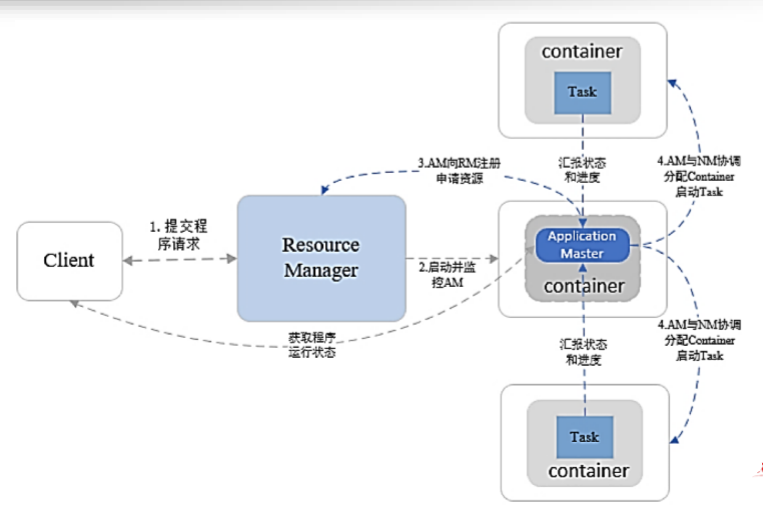
- 客户端提交Task请求到RM
- RM先到NM上启动1个Container,用来运行AM,并监控AM
- AM启动后,向RM注册(任务是由AM管理的,注册之后,用户就可以通过RM查询AM上的作业进度)并向NM申请资源(Core Memory),申请资源,RM给AM分配响应的NM资源
- AM下发指令给相应的的NM,与NM协调分配Container,NM启动Container,启动并运行task
3.2 高可用
ResourceManager高可用
- 一个Active RM,多个Standby RM
- Active RM宕机后自动实现主备切换
- Zookeeper的核心作用:
- Active节点选举
- 恢复Active RM的原有状态信息
- 重启AM,杀死所有运行中的Container
- 切换方式:手动、自动
四、 YARN资源调度策略
4.1 FIFO调度器
FIFO Scheduler(先进先出调度器)
调度策略
- 将所有任务放入一个队列,先进队列的先获得资源,排在后面的任务只有等待。
缺点
- 资源利用率差,无法交叉运行任务
- 灵活性差,如:紧急任务无法插队,耗时长的任务拖慢耗时短的任务
4.2 容量调度器
Capacity Scheduler(容量调度器)
核心思想
- 提前做预算,在预算指导下分享集群资源
调度策略
- 集群资源由多个队列分享
- 每个队列都要预设资源分配的比例(提前做预算)
- 空闲资源优先分配给“实际资源/预算资源”比值最低的队列
- 队列内部采用FIFO调度策略
特点
- 层次化的队列设计:子队列可使用父队列资源
- 容量保证:每个队列都要预设资源占比,防止资源独占
- 弹性分配:空闲资源可以分配给任何队列,当多个队列争用时,会按比例进行平衡
- 支持动态管理:可以动态调整队列的容量、权限等参数,也可动态增加、暂停队列
- 访问控制:用户只能向自己的队列中提交任务,不能访问其他队列
- 多租户:多用户共享集群资源
4.3 公平调度器
Fair Scheduler(公平调度器)
调度策略
- 多队列公平共享集群资源
- 通过平分的方式,动态分配资源,无需预先设定资源分配比例
- 队列内部可配置调度策略:FIFO、Fair(默认)
资源抢占
- 终止其他队列的任务,使其让出所占资源,然后将资源分配给占用资源量少于最小资源量限制的队列
队列权重
- 当队列中有任务等待,并且集群中有空闲资源时,每个队列可以根据权重获得不同比例的空闲资源
五、 YARN运维与监控
5.1 YARN运维
Shell命令: yarn application [command_options]
command_options如-list、-kill、-status
Kill任务
- CTRL+C不能终止任务,只是停止其在控制台的信息输出,任务仍在集群中运行
- 正确方法:先使用yarn application -list获取进程号,再使用-kill终止任务
5.2 YARN监控
- 访问Resource Manager的8088端口,进入监控页面
六、 综述
(一)
YARN 是 Hadoop 2.0 中的资源管理系统,基本设计思想是将 JobTracker 拆分成了两个独立的服务:一 个全局的资源管理器 ResourceManager 和每个应用程序特有的 ApplicationMaster。其中 ResourceManager 负责整个系统的资源管理和分配,而 ApplicationMaster 负责单个应用程序的管理。
YARN 总体上仍然是 master/slave 结构,在整个资源管理框架中,ResourceManager 为 master, NodeManager 是 slave。Resourcemanager 负责对各个 NodeManager 上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的任务。由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。
YARN 的基本组成结构:YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等几个组件构成。
- ResourceManager 是 Master 上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等;
- NodeManager 是 Slave 上一个独立运行的进程,负责上报节点的状态;
- Application Master 和 Container 是运行在 Slave 上的组件,Container 是 YARN 中分配资源的一个单位,包涵内存、CPU YARN 以 Container 为单位分配资源。
Client 向 ResourceManager 提交的每一个应用程序都必须有一个 Application Master,它经过 ResourceManager 分配资源后,运行于某一个 Slave 节点的 Container 中,具体做事情的 Task,同样也运行与某一个 Slave 节点的 Container 中。RM,NM,AM 乃至普通的 Container 之间的通信,都是用 RPC 机制。
YARN 的架构设计使其越来越像是一个云操作系统,数据处理操作系统。
(二)
当用户向 YARN 中提交一个应用程序后,YARN 将分两个阶段运行该应用程序: 第一个阶段是启动 ApplicationMaster; 第二个阶段是由 ApplicationMaster 创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。 如下图所示,YARN 的工作流程分为以下几个步骤:
- 用户向 YARN 中提交应用程序,其中包括ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
- ResourceManager 为该应用程序分配第一个 Container,并与对应的 NodeManager 通信,要求它在这个 Container 中启动应用程序的 ApplicationMaster。
- ApplicationMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤 4~7。
- ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
- 一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务。
- NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过 RPC 向 ApplicationMaster 查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
参考资料
[1]让 Hadoop 称霸至今的框架 –Hadoop Yarn
[2]分布式资源管理器YARN简介(一)
[3]分布式资源管理系统:YARN
[4]YARN 分布式资源调度