大数据理论篇 | 分布式文件系统HDFS
一、 HDFS简介
概念
- HDFS即Hadoop分布式文件系统(Hadoop Distributed File System)
- 2003年10月Google发表了GFS(Google File System)论文
- HDFS是GFS的开源实现
- HDFS是Apache Hadoop的核心子项目
- HDFS是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上
- 在开源大数据技术体系中,地位无可替代
设计目标
- 运行在大量廉价商用机器上:硬件错误是常态,提供容错机制
- 简单一致性模型:一次写入多次读取,支持追加,不允许修改,保证数据一致性
- 流式数据访问:批量读而非随机读,关注吞吐量而非时间
- 存储大规模数据集:典型文件大小GB - TB,关注横向线性扩展
优点
- 高容错、高可用、高扩展
- 采用数据冗余,多Block多副本,副本丢失后自动恢复
- 引入NameNode High Availability(HA)解决方案,引入安全模式
- 10K节点规模
- 支持海量数据存储
- 典型文件大小GB - TB,百万以上文件数量,PB以上数据规模
- 构建成本低,安全可靠
- 构建在廉价的商用服务器上
- 提供了容错和恢复机制
- 适合大规模离线批处理
- 流式数据访问机制
- 数据位置暴露给计算框架
缺点
不适合低延迟数据访问
不适合大量小文件存储
- 因为元数据占用NameNode大量内存空间,每个文件、目录和Block的元数据都要占用150Byte,若存储1亿个元素,大约需要20GB内存,如果一个文件为10KB,1亿个文件大小仅有1TB,却要消耗掉20GB内存
- 不支持并发写入
- 一个文件同时只能有一个写入者
- 不支持文件随机修改,仅支持追加写入
二、 HDFS原理
系统架构
HDFS由四部分组成:HDFS Client、DataNode、Active NameNode(AM)和Standby NameNode(SN)。
HDFS是一个主/从(Mater/Slave)体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。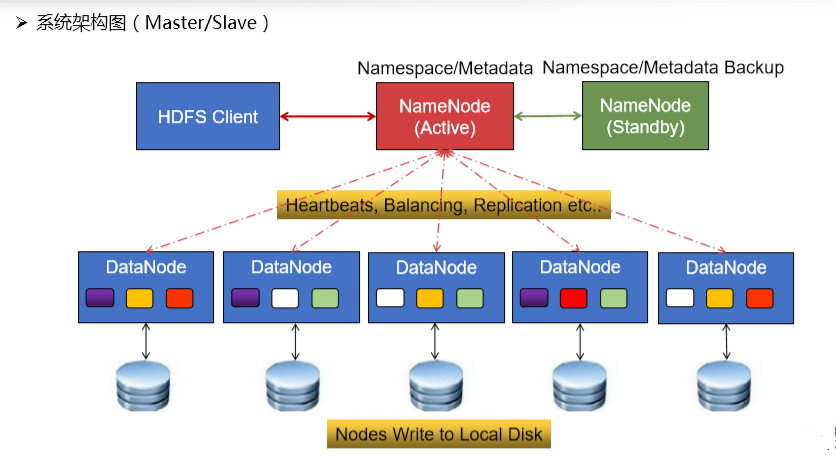
基本概念
Active NameNode(AN)
- 活动Master管理节点(集群中唯一)
- 管理文件系统的命名空间(NameSpace)
- 管理元数据:文件的位置、所有者、权限、数据块等
- 管理配置Block副本策略:默认3个副本
- 处理客户端读写请求,为DataNode分配任务
- HDFS的守护进程
Standby NameNode(SN)
- 热备Master管理节点(Active NameNode的热备节点)
- 在Hadoop 3.0中允许配置多个Standby NameNode
- Active NameNode宕机后,快速升级为新的Active
- 定期同步元数据,即周期性下载edits编辑日志,生成fsimage镜像检查点文件,合并fsimage和editslog,推送给NameNode
NameNode元数据文件
- edits(编辑日志文件):保存了自最新检查点(Checkpoint)之后的所有文件更新操作
- fsimage(元数据检查点镜像文件):保存了文件系统中所有的目录和文件信息,如:某个目录下有哪些子目录和文件,以及文件名、文件副本数、文件由哪些Block组成等
- Active NameNode内存中有一份最新的元数据(= fsimage + edits)
- Standby NameNode在检查点定期将内存中的元数据保存到fsimage文件中
DataNode
- Slave工作节点,可大规模扩展
- 存储实际的数据Block和数据校验和
- 执行客户端发送的读写操作
- 通过心跳机制定期(默认3秒)向NameNode汇报运行状态和Block列表信息
- 集群启动时,DataNode向NameNode提供Block列表信息
Block数据块
- HDFS最小存储单元
- 文件写入HDFS会被切分成若干个Block,分散存储在集群的不同的数据节点DataNode上,需要注意的是,这个操作是HDFS自动完成的
- Block大小固定,默认128MB,可自定义
- 若一个Block的大小小于设定值,不会占用整个块空间
- 默认情况下每个Block有3个副本
Client
- 将文件切分为Block
- 与NameNode交互,获取文件访问计划和相关元数据
- 与DataNode交互,读取或写入文件
- 管理HDFS
存储机制
1)数据文件存储
Block存储:
- Block是HDFS的最小存储单元
- 如何设置Block大小呢?目标是最小化寻址开销(降到1%以下),默认大小是128MB,块若设置得太小,则寻址时间占比过高;若块设置得太大,则Map任务数太少,并发度降低,作业执行速度变慢。
- Block和元数据分开存储,Block存储于DataNode,元数据存储于NameNode
- Block多副本,以DataNode节点为备份对象
- 机架感知:将副本存储到不同的机架上,实现数据的高容错
- 副本均匀分布:提高访问带宽和读取性能,实现负载均衡
Block副本放置策略
- 副本1:放在Client所在节点。对于远程Client,系统会随机选择节点
- 副本2:放在不同的机架节点上
- 副本3:放在与第二个副本同一机架的不同节点上
- 副本N:随机选择
- 节点选择:同等条件下优先选择空闲节点
Block文件
- Block文件是DataNode本地磁盘中名为“blk_blockId”的Linux文件
- Block元数据文件(* .meta)由一个包含版本、类型信息的头文件和一系列校验值组成
2)元数据存储
元数据存储的两者形式
- 内存元数据(NameNode)
- 文件元数据(edits+fsimage)
edits(编辑日志文件)
- Client请求变更操作时,操作首先被写入edits,再写入内存
- edits文件名通过前/后缀记录当前操作的Transaction Id
fsimage(元数据镜像检查点文件)
- 不会为文件系统的每个更新操作进行持久化,因为写fsimage的速度非常慢
- fsimage文件名会标记对应的Transaction Id
edits和fsimage的合并机制
Hadoop1.x
- 在NameNode运行期间,HDFS的所有更新操作都是直接写入edits文件中,因此edits文件将变得很大,虽然这对NameNode运行时影响不大,但是在NameNode重启时,NameNode会先将fsimage里的所有内容映射到内存中,然后再一条一条地执行edits中的操作记录,当edits文件非常大时,会导致NameNode启动操作非常慢,并且这段时间HDFS系统处于安全模式,无法满足用户要求。
- 在Hadoop1.x版本中有个Secondary NameNode进程,它不完全是Primary NameNode的热备进程,它是HDFS架构的一个组成部分,用来保存NameNode中元数据metadata的备份,一般是将其单独运行在一台机器上的。
- Secondary NameNode会定期和Primary NameNode通信,请求其停止使用edits文件,暂时将新的写操作写到一个新的edits.new文件中,这个操作是瞬间完成的,上层写日志的函数完全感觉不到这个差别
- Secondary NameNode通过HTTP GET方式从Primary NameNode中获取fsimage和edits文件,并将其下载到本地的相应目录下
- Secondary NameNode将下载完成的fsimage载入到内存中,然后逐条执行edits文件中的各项更新操作,使得内存中的fsimage文件保持最新,这个过程就是edits和fsimage文件的合并
- Secondary NameNode执行完第三步的操作后,通过POST方式将新的fsimage.ckpt文件发送到Primary NameNode节点上
- Primary NameNode用从Secondary NameNode接收到的新的fsimage文件替换旧的fsimage文件,同时用edits.new文件替换edits文件,通过这个过程就减小了edits文件大小,加快了NameNode的重启速度
- 从上面的描述可以发现,Secondary NameNode并不是Primary NameNode的一个热备,它主要负责将fsimage和edits文件合并。其拥有的fsimage文件并不是最新的,因为当它从Primary NameNode中下载fsimage和edits文件时,新的更新操作已经写入edits.new文件中了,这些更新在Secondary NameNode中并没有同步到。
- 如果Primary NameNode中的fsimage真的出问题了,还是可以用Secondary NameNode中的fsimage替换一下的,虽然不是最新的fsimage,但是可以将损失降至最低。
Hadoop2.x
- 在Hadoop2.x中解决了Primary NameNode的单点故障问题,并且弃用了Secondary NameNode。
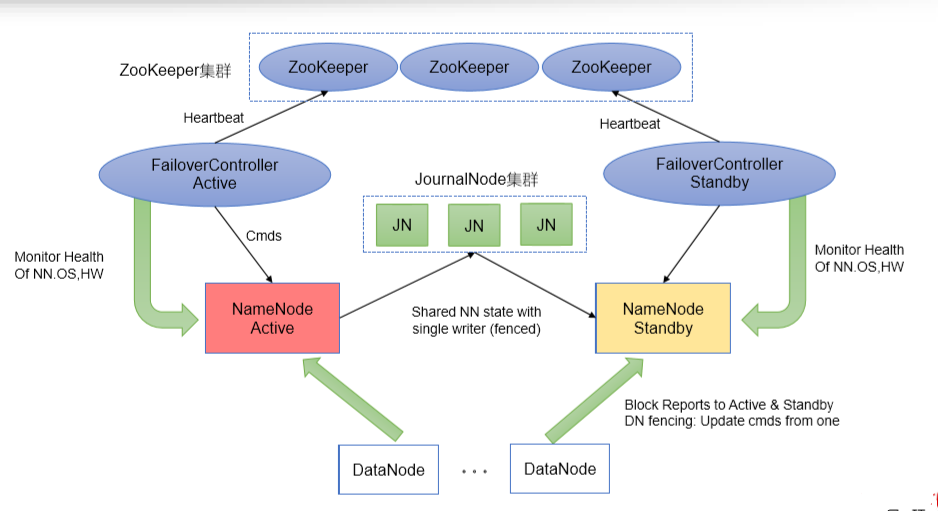
- 在Hadoop2.x中提供了HA机制(解决NameNode单点故障,提供高可用机制),通过配置奇数个JournalNode来实现HA。
- HA机制通过在同一个集群中运行两个NameNode(Active NameNode、Standby NameNode),来解决NameNode单点故障问题。在任何时间,只有一台机器处于Active状态,另一台机器处于standby状态。Active NN负责接收集群中所有客户端的操作,Standby NN主要用于备用,需要保证StandbyNN中的状态和Active NN的状态尽可能同步,从而可以快速提供故障恢复。
- 为了保证StandbyNN中的状态和Active NN的状态尽可能同步,即元数据保持一致,它们都会与Journal Nodes守护进程通信。当Active NN执行任何有关文件系统NameSpace的修改操作时,它需要持久化到一半以上(大多数)的Journal Nodes上(通过edits持久化存储),而Standby NN负责观察edits文件的变化,它能够从Journal Node集群中读取edits信息,并更新其内部的NameSpace。一旦Active NN出现了故障,Standby NN会保证从Journal Nodes集群中读取出了全部的edits文件,然后切换成Active状态,从而保证Standby NN和Actvie NN拥有完全同步的NameSpace状态。
- 实现fsimage和edits文件合并的机制
- 在Standy NameNode节点上会一直运行一个叫做CheckpointerThread的线程,这个线程调用StandbyCheckpointer类的doWork()函数,该函数会每隔Math.min(checkpointCheckPeriod, checkpointPeriod)秒来执行一次合并操作。这两个时间可以通过配置文件进行配置
- 具体步骤:
- Active NN提交edits log到JournalNode集群中
Active NN同时向本地磁盘目录和JournalNode集群上的共享目录中写入edits log,这里是同步地向本地和JN集群中写入edits日志,向JN集群中写edits时是并行写的。只要向大多数的JN写入edits文件成功,就认为此次提交edits文件成功,否则认为提交失败,导致Active NN退出进程,Standby NN接管之后进行数据恢复 - Standby NN从Journal Node集群中同步edits文件
Standby NN定期从Journal Node集群中下载edits文件放到节点的内存中,然后Standby NameNode中的StandbyCheckpointer类会定期检查合并的条件是否成立,如果成立则会合并fsimage和edits文件(checkpoint机制)。Standby NameNode中的StandbyCheckpointer类合并完之后,将合并之后的fsimage上传到Active NameNode相应目录中。Active NameNode接到最新的fsimage文件之后,将旧的fsimage和edits文件清理掉;
- Active NN提交edits log到JournalNode集群中
参考阅读
[1]Hadoop-2.X HA模式下的FSImage和EditsLog合并过程
[2]HDFS fsimage和edits合并实现原理
读操作 从HDFS中读取内容
综述:客户端将要读取的文件路径发送给NameNode,NameNode获取文件的元信息(主要是Block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应DataNode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
具体:
- 客户端跟NameNode通信,发送文件路径,请求读取文件
- NameNode检查文件目录树,查询文件块组成,查询文件块与DataNode的映射关系。【获取文件的元数据信息(Block所在的DataNode节点信息)】
- 按照DataNode与客户端的距离由近到远的顺序列表返回给客户端。
- 客户端与最近的DataNode建立连接,请求建立Socket流
- DataNode将文件Block数据返回给客户端
- 客户端在本地将组成文件的Block拼接成一个文件
写操作 向HDFS中写入内容
- 客户端向NameNode请求上传文件,请求NameNode在NameSpace中建立新的文件元信息
- NameNode检查目录,检查目标文件是否已存在,父目录是否存在,是否具有权限,是否有足够资源等
- NameNode返回是否允许上传,若通过检查,直接先将操作写入EditLog,并返回输出流对象。 (WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作)
- 客户端将文件切分为Block(默认128MB一个块)
- 客户端请求第一个Block该传输到哪些DataNode服务器上
- NameNode从DataNode信息池中检查DataNode信息
- NameNode返回分配的可写的DataNode列表
- 客户端请求建立Block传输管道,请求一台DataNode上传数据(本质上是一个RPC调用,建立pipeline),第一个DataNode收到请求会继续调用第二个DataNode,然后第二个调用第三个DataNode,将整个pipeline建立完成,逐级返回客户端
- 客户端以packet为单位发送第一个Block的数据,在写入的时候DataNode会进行数据校验,它并不是通过一个packet(64kb)进行一次校验而是以chunk为单位进行校验(512byte),第一台DataNode收到一个packet就会传给第二台,第二台传给第三台;第一台每传一个packet会放入一个应答队列等待应答。最后返回写入成功。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器
相关链接
[1]HDFS读写文件流程
[2]HDFS写数据和读数据流程
[3]HDFS 读写流程与数据完整性
安全模式
什么是安全模式
- 安全模式是HDFS的一种特殊状态,在这种状态下,HDFS只接收读数据请求,而不接收写入、删除、修改等变更请求
- 安全模式是HDFS确保Block数据安全的一种保护机制
- Active NameNode启动时,HDFS会进入安全模式,DataNode主动向NameNode汇报可用Block列表等信息,在系统达到安全标准前,HDFS一直处于“只读”状态
何时正常离开安全模式
- Block上报率:DataNode上报的可用Block个数 / NameNode元数据记录的Block个数
- 当Block上报率 >= 阈值时,HDFS才能离开安全模式,默认阈值为0.999
- 不建议手动强制退出安全模式
触发安全模式的原因
- NameNode重启
- NameNode磁盘空间不足
- Block上报率低于阈值
- DataNode无法正常启动
- 日志中出现严重异常
- 用户操作不当,如:强制关机(特别注意!)
HDFS高可用
- Active NN与Standby NN的主备切换
- 利用QJM实现元数据高可用
- QJM机制(Quorum Journal Manager):只要保证Quorum(法定人数)数量的操作成功,就认为这是一次最终成功的操作(大多数)
- QJM共享存储系统:部署奇数(2N+1)个JournalNode,JournalNode负责存储edits编辑日志,写edits的时候,只要超过半数(≥N+1)的JournalNode返回成功,就代表本次写入成功,因此最多可容忍N个JournalNode宕机,这是基于Paxos算法的实现。
- 利用ZooKeeper实现Active节点选举
参考阅读
[1]NameNode HA实现原理
[2]Hadoop NameNode 高可用 (High Availability) 实现解析
[3]Hadoop HDFS高可用(HA)
[4]HDFS的运行原理,如何实现HDFS的高可用
HDFS 文件管理
Shell命令
语法
- hadoop fs
(使用面最广,可以操作任何文件系统) - hdfs dfs
(只能操作HDFS文件系统) - 大部分用法和Linux Shell类似,可通过help查看帮助
如:
- hadoop fs -ls [-d] [-h] [-R]
- hadoop fs -get [-ignorecrc] [-crc]
: 拷贝文件到本地文件系统 - hadoop fs -put
… : 从本地文件系统上传文件到模板文件系统 - hadoop fs -cp [-f] [-p | -p[topax]] URI [URI …]
- hadoop fs -mv URI [URI …]
- hadoop fs -rm [-f] [-r |-R] [-skipTrash] URI [URI …]
HDFS URI
- 格式:scheme://authority/path
- 示例:HDFS上的一个文件/parent/child
Rest API
- HDFS的所有接口都支持REST API
- HDFS URI与HTTP URL
- hdfs://
:<RPC_PORT>/ - http://
:<HTTP_PORT>/webhdfs/v1/ ?op=…
- hdfs://
HDFS 系统管理
系统监控
- Active NameNode WebUI
- http://activeNameNodeHost:50070
- 端口是50070
参考资料
[1]带你入坑大数据(一) — HDFS基础概念篇
[2]Hadoop Distributed File System 简介
[3]HDFS知识点总结
[4]HDFS