LeetCode-146.LRU缓存机制
题目描述
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。 写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
题目难度
中等
进阶
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例
1 | LRUCache cache = new LRUCache( 2 /* 缓存容量 */ ); |
题目分析
1. LRU机制
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。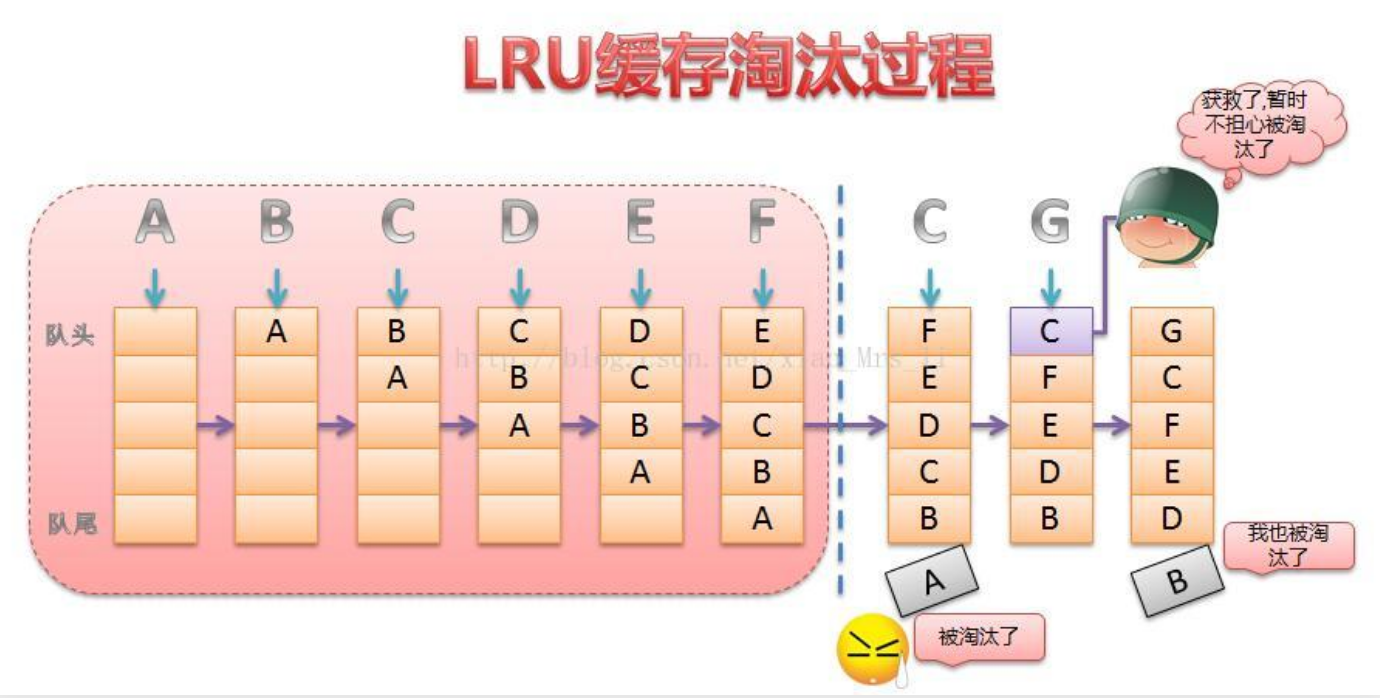
阅读文章:LRU算法 缓存淘汰策略
2. 分析
LRUCache最简单的实现是单链表
- 假设链表头部优先级高,尾部优先级低
- get元素时,同时将该元素移动到链表首部
- put元素时,先查找
- 如果没有找到,直接添加到链表首部。
- 如果找到了,移除原来元素,将新元素插入链表首部。
- 如果Cache已满,移除链表尾部结点
这种做法时间复杂度太高,为O(n),题目要求使用时间复杂度O(1)完成。
由于双向链表的插入复杂度为O(1), hashMap的查找复杂度也为O(1),符合题意。因此,数据结构先选用HashMap+双向链表。
Java中LinkedHashMap是一种结合了哈希表和链表结构。
实现
方法1. HashMap+Java内置双向链表
以下使用的是Java内置的双向链表:LinkedList
学习LinkedList可以参考:
[1]Java 集合系列05之 LinkedList详细介绍(源码解析)和使用示例
[2]A Guide to the Java LinkedList
[3]LinkedList in Java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public class LRUCache {
private LinkedList<ListNode> nodeList = new LinkedList<>();
private Map<Integer, ListNode> map = new HashMap<>();
private int capacity = 0;
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
ListNode node = map.get(key);
if (node == null) {
return -1;
}
nodeList.remove(node);
nodeList.add(node);
return node.value;
}
public void put(int key, int value) {
ListNode node = new ListNode(key, value);
if (map.containsKey(key)) {
nodeList.remove(node);
}
nodeList.add(node);
if (nodeList.size() > capacity) {
ListNode old = nodeList.removeFirst();
map.remove(old.key);
}
map.put(key, node);
}
private class ListNode {
private int key;
private int value;
public ListNode(int key, int value) {
this.key = key;
this.value = value;
}
public boolean equals(Object obj) {
ListNode node = (ListNode) obj;
return this.key == node.key;
}
}
}
执行用时:415 ms
内存消耗:65.8 MB
方法2. HashMap+自己实现双向链表
这参照了LeetCode官方题解。官方题解中采用了HashTable,这里改成了HashMap,结合双向链表来实现。
注意,这里使用一个伪头部和伪尾部标记界限,这样在更新的时候就不需要检查是否是 null 节点。
这里认为链表头部优先级最高,尾部优先级最低,因此cache满的时候移除链表尾部元素。
1 | public class LRUCache { |
执行用时:134 ms
内存消耗:54.2 MB
复杂度分析
- 时间复杂度:对于 put 和 get 都是 O(1)O(1)。
- 空间复杂度:O(capacity)O(capacity),因为哈希表和双向链表最多存储 capacity + 1 个元素。
方法3. 有序字典LinkedHashMap
有一种叫做有序字典的数据结构,综合了哈希表和链表,在 Python 中为 OrderedDict,在 Java 中为 LinkedHashMap。
HashMap 是无序的,HashMap 在 put 的时候是根据 key 的 hashcode 进行 hash 然后放入对应的地方。所以在按照一定顺序 put 进 HashMap 中,然后遍历出 HashMap 的顺序跟 put 的顺序不同(除非在 put 的时候 key 已经按照 hashcode 排序号了,这种几率非常小)
LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap。
LinkedHashMap 是 Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap 实现与 HashMap 的不同之处在于,LinkedHashMap 维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用 get 方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
Java的容器LinkedHashMap底层也使用了LRU算法,下面的程序是使用LinkedHashMap的解法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
执行用时:139 ms
内存消耗:54.2 MB
复杂度分析
- 时间复杂度:对于 put 和 get 操作复杂度是 O(1)O(1),因为有序字典中的所有操作:get/in/set/move_to_end/popitem(get/containsKey/put/remove)都可以在常数时间内完成。
- 空间复杂度:O(capacity)O(capacity),因为空间只用于有序字典存储最多 capacity + 1 个元素。
有关LinkedHashMap的资料参考:
[1]Map 综述(二):彻头彻尾理解 LinkedHashMap
[2]LRU缓存实现(Java)
[3]LinkedHashMap 的实现原理
参考资料
[1]官网题目链接
[2]LeetCode - 146. LRU Cache(LRU缓存变更算法)(LinkedHashMap底层)
[3]LRUCache.java
[4]LeetCode 第 146 号问题:LRU缓存机制
[5]LeetCode 第 146 号问题:LRU缓存机制